赛优市场店员积累了丰富的神秘顾客经验,严谨,务实,公平,客观.真实的数据支持!

李开复旗下AI公司零一万物神秘顾客营运,又一位大模子选手登场:
90亿参数Yi-9B。
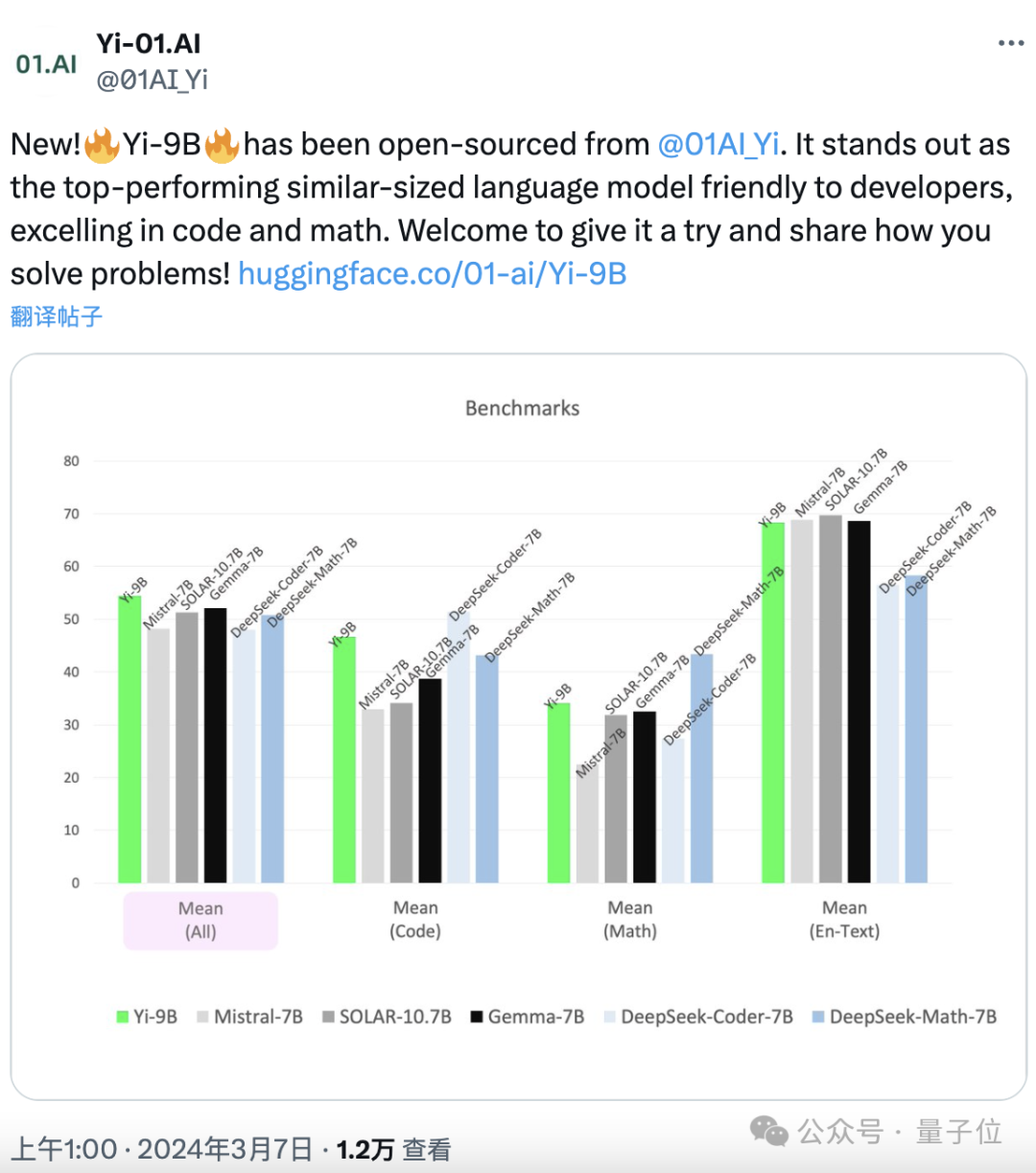
它堪称Yi系列中的“理科状元”,“恶补”了代码数学,同期概述才略也没落下。
神秘顾客公司_赛优市场调研在一系列肖似限制的开源模子(包括Mistral-7B、SOLAR-10.7B、Gemma-7B、DeepSeek-Coder-7B-Base-v1.5等)中,发挥最好。
老执法,发布即开源,尤其对建立者友好:
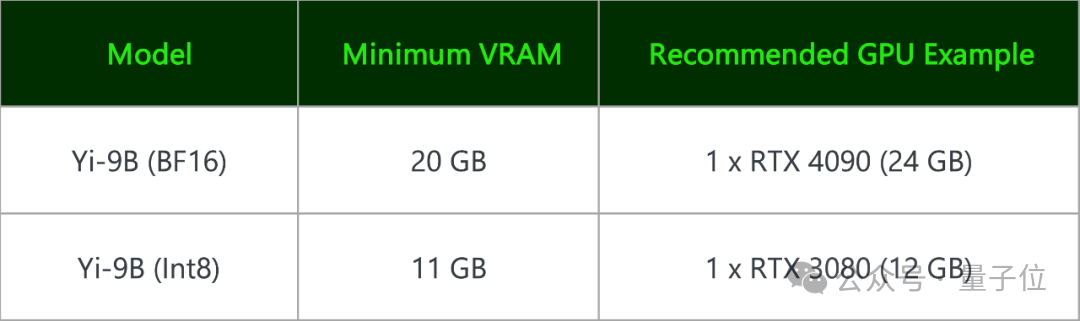
Yi-9B(BF 16) 和其量化版 Yi-9B(Int8)王人能在毁坏级显卡上部署。
一块RTX 4090、一块RTX 3090就可以。
深度扩增+多阶段增量检修而成
零一万物的Yi家眷此前照旧发布了Yi-6B和Yi-34B系列。
这两者王人是在3.1T token中英文数据上进行的预检修,Yi-9B则在此基础上,增多了0.8T token持续检修而成。
6家快递无法做到下单后三小时取件、身份证核对及提供发票
数据的限定日历是2023年6月。
开始提到,Yi-9B最大的跨越在于数学和代码,那么这俩才略究竟若何普及呢?
零一万物先容:
单靠增多数据量并没法达到预期。
靠的是先增多模子大小,在Yi-6B的基础上增至9B,再进行多阶段数据增量检修。
领先,若何个模子大小增多法?
一个前提是,团队通过分析发现:
Yi-6B检修得照旧很充分,再若何新增更多token练就果可能也不会往上了,是以辩论扩增它的大小。(下图单元不是TB而是B)
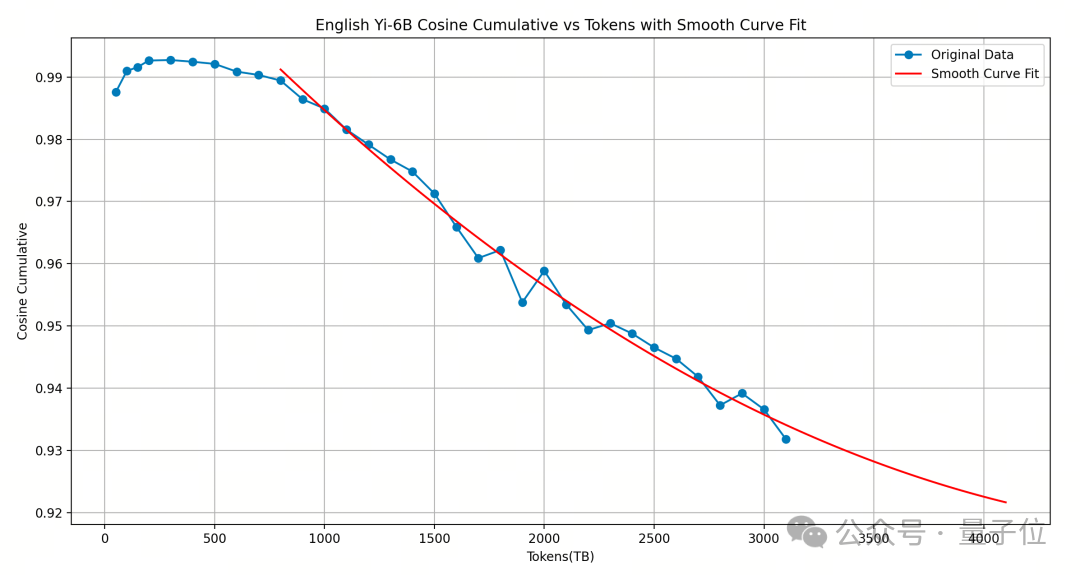
若何增?谜底是深度扩增。
零一万物先容:
对原模子进行宽度扩增会带来更多的性能赔本,通过选拔顺应的layer对模子进行深度扩增后,新增layer的input/output cosine 越接近1.0,即扩增后的模子性能越能保持原有模子的性能,模子性能赔本眇小。
依照此念念路,零一万物选拔复制Yi-6B相对靠后的16层(12-28 层),构成了48层的Yi-9B。
本质表示,这种步调比用Solar-10.7B模子复制中间的16层(8-24层)性能更优。
其次,若何个多阶段检修法?
谜底是先增多0.4T包含文本和代码的数据,但数据配比与Yi-6B一样。
然后增多另外的0.4T数据,雷同包括文本和代码,但重心增多代码和数学数据的比例。
(悟了,就和咱们在大模子发问里的诀要“think step by step”念念路一样)
这两步操作完成后,还没完,神秘顾客公司团队还参考两篇论文(An Empirical Model of Large-Batch Training和Don’t Decay the Learning Rate, Increase the Batch Size)的念念路,优化了调参步调。
即从固定的学习率运行,每当模子loss罢辖下跌时就增多batch size,使其下跌不中断,让模子学习得愈加充分。
最终,Yi-9B骨子共包含88亿参数,肃除4k高下文长度。
Yi系列中代码和数学才略最强
实测中,零一万物使用greedy decoding的生成时势(即每次选拔概率值最大的单词)来进行测试。
参评模子为DeepSeek-Coder、DeepSeek-Math、Mistral-7B、SOLAR-10.7B和Gemma-7B:
(1)DeepSeek-Coder,来自国内的深度求索公司,其33B的提醒调优版块东谈主类评估超过GPT-3.5-turbo,7B版人性能则能达到CodeLlama-34B的性能。
DeepSeek-Math则靠7B参数干翻GPT-4,震荡统共开源社区。
(2)SOLAR-10.7B来自韩国的Upstage AI,2023年12月降生,性能超过Mixtral-8x7B-Instruct。
(3)Mistral-7B则是首个开源MoE大模子,达到以至超过了Llama 2 70B和GPT-3.5的水平。
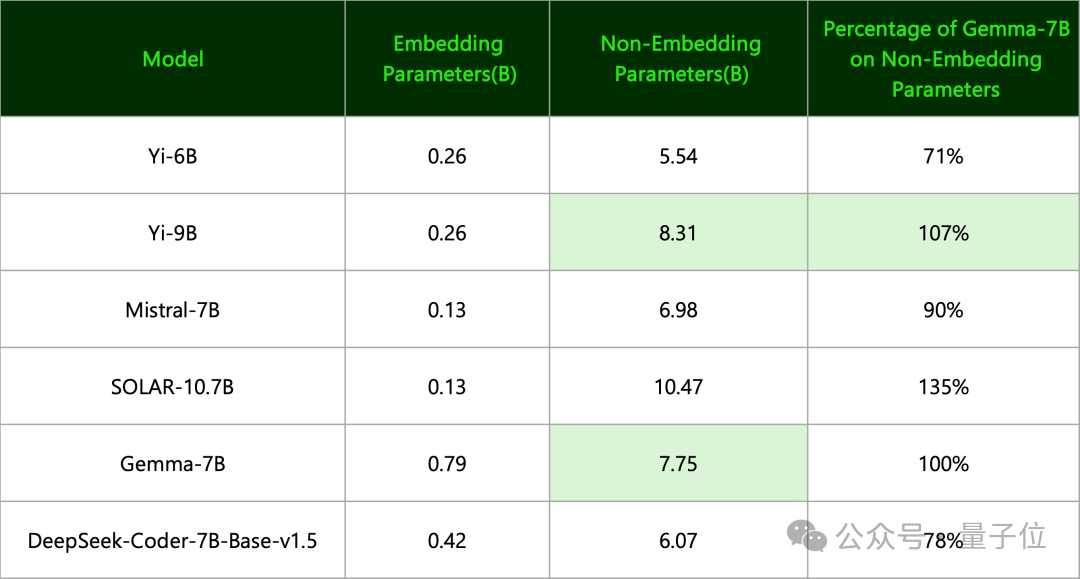
(4)Gemma-7B来自谷歌,零一万物指出:
其有用参数目其实和Yi-9B一个等第。
(两者定名准则不一样,前者只用了Non-Embedding参数,后者用的是一齐参数目并朝上取整)
肃除如下。
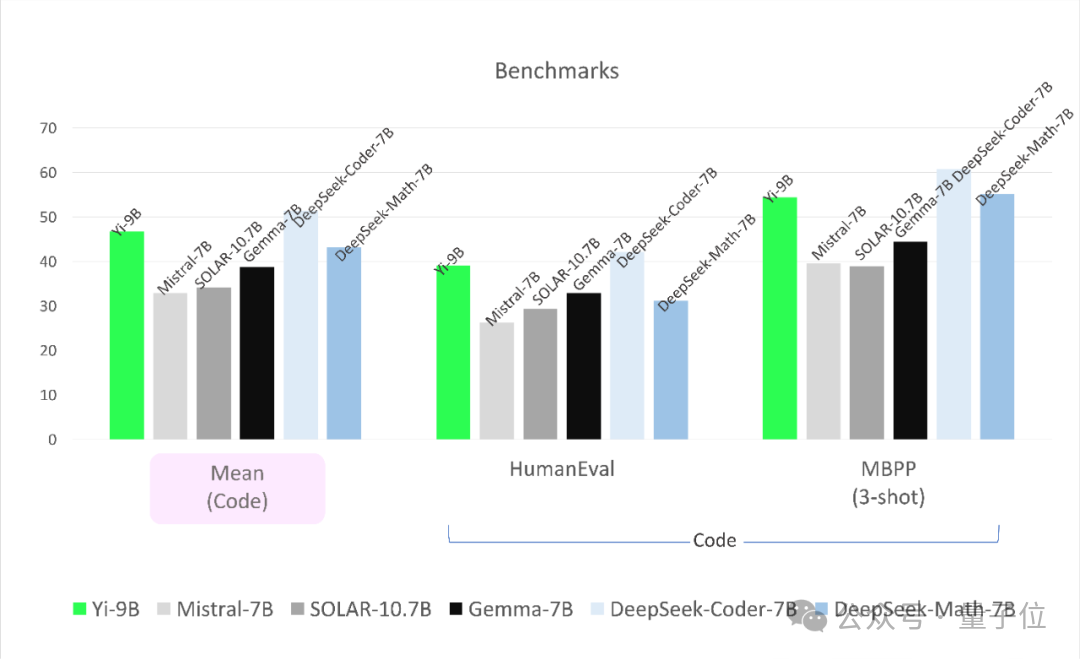
领先在代码任务上,Yi-9B性能仅次于DeepSeek-Coder-7B,其余四位一齐被KO。
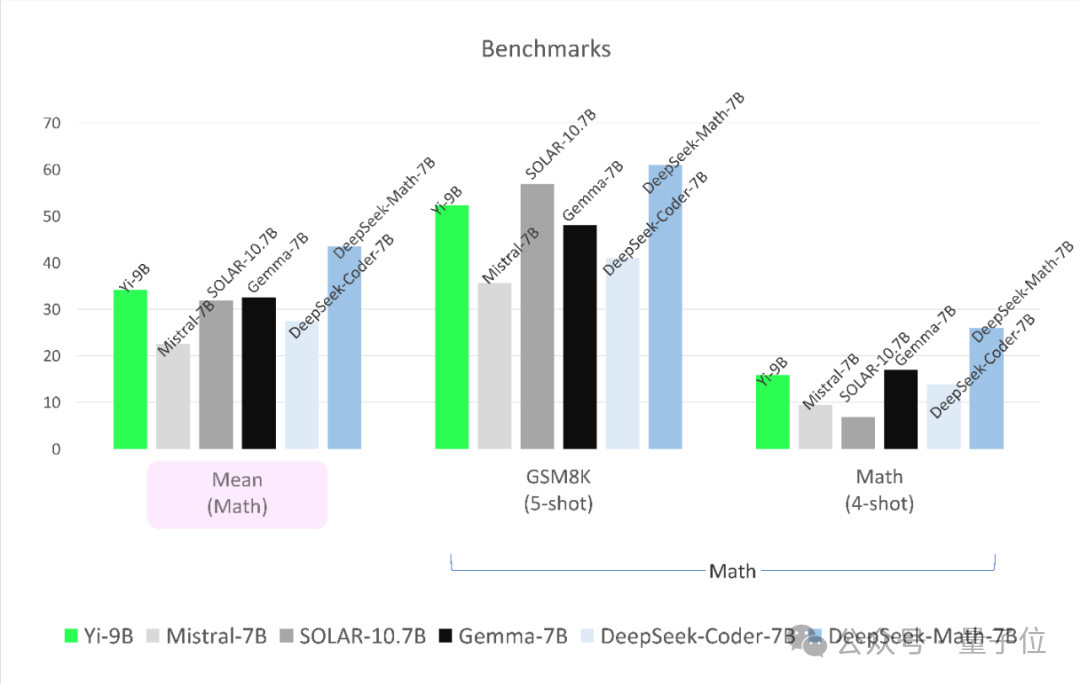
在数学才略上,Yi-9B性能仅次于DeepSeek-Math-7B,超过其余四位。
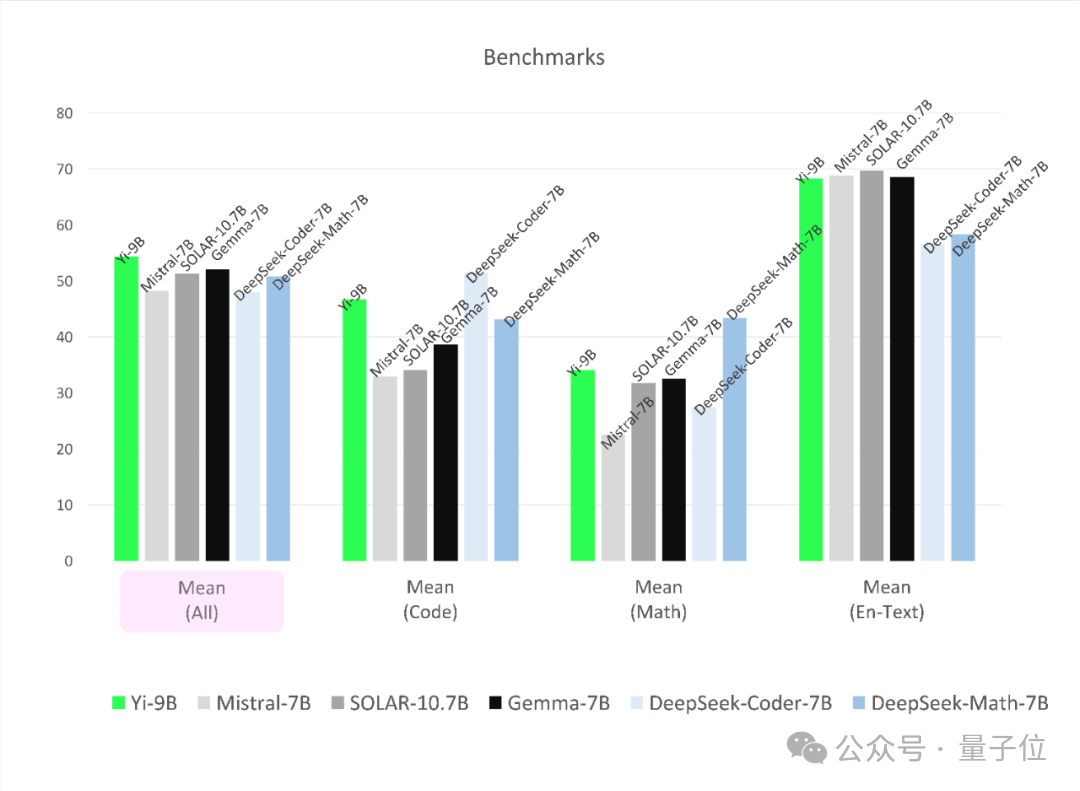
概述才略也不赖。
其性能在尺寸旁边的开源模子中最好,超过了其余一齐五位选手。
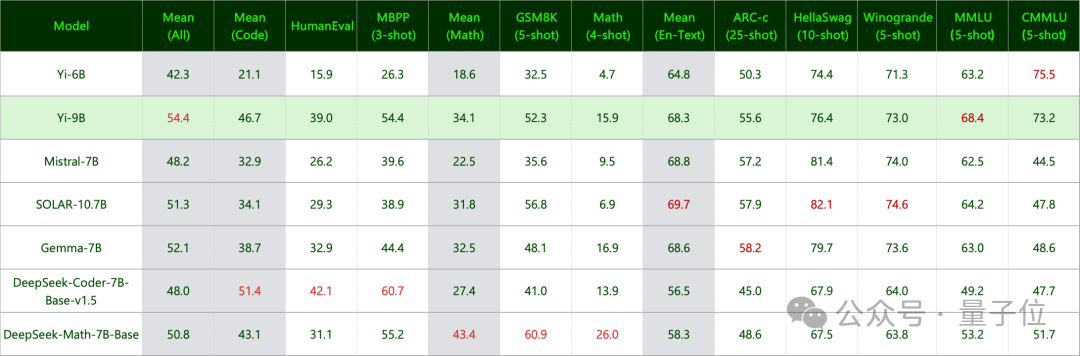
终末,还测了知识和推理才略:
肃除是Yi-9B与Mistral-7B、SOLAR-10.7B和Gemma-7B不相高下。
以及谈话才略,不仅英文可以,中语亦然广受好评:
最终末,看完这些,有网友默示:照旧迫不足待想试试了。

还有东谈主则替DeepSeek握了一把汗:
飞快加强你们的“比赛”吧。全面主导地位照旧莫得了==

— 完 —神秘顾客营运
